
Azure CosmosDB pricing explained
Pricing of this service is not so complicated as it looks on the first try – you pay for two parameters together – for saved document size ($0.25 per GB) + for reserved database performance (throughput) – in Request Units (RU) / second unit.
Minimum performance you have to reserve is 400 RU/s ($0.008 per 1 hour), scaleable by 100 RU/s.
Pricing #1 per document collection
In this pricing mode, you pay for reserved performance per every document collection.
So at the minimum, you will pay for every document collection in your database $23.61 per month (400 RU/s, 1GB storage, Single Region Write).
You can scale performance for every collection separately. But if you don’t fill up reserved performance, you are wasting your money.
Pricing #2 per database
Azure also provides alternative pricing – you can set up reserved performance for whole database. This reserved performance is shared across all collections in database. Minimum is again 400 RU/s
Every collection needs to have at least 100 RU/s – so first 4 collections are included, extra collection will cost you +100 RU/s per collection.
And small note, this pricing mode has one extra requirement – you need to have shard key in all your collections.
Pricing-problematic use case
Imagine you want to migrate f.ex. application, which has 10x MongoDB entity types (collections).
By pricing mode #1 you get amount $233.6 per month (400 RU/s per collection = 4000 RU/s in total) By pricing mode #2 you get amount $58.4 per month (1000 RU/s in total) – both without storage cost
That could be ok for some kind of applications. But what if I have application, which has some primary collections with frequent access and some supportive collections with infrequent access?
So you can join the group of users, who pay $23.61 per month per every infrequent collection. Or you able to not use CosmosDB for infrequent collections, but I would have to manage another connection to another database service, care about SLAs etc.
First reasonable solution is to use the pricing mode #2, but you have to pay at least 100 RU/s per every collection, so if you have a lot of infrequent collections, you still going to pay too much.
Solution based on MongoDB discriminators
When I read the pricing description in detail, I got an idea:
What about put all entities in one collection and mark into BSON serializated entity their type and use it during deserialization?
One of my friend reminded me, that MongoDB C# SDK (MongoDB SDKs for almost every language) already have built-in feature called discriminator. This feature allows you to use polymorphism on entites saved to MongoDB database (more info).
| |
The idea is simple – I am going to create only one collection in pricing mode #1 (with 400RU/s), where are located entities across all infrequent collections.
Example implementation in MongoDB .NET SDK
ACommonStoredEntityModel.cs
| |
Category.cs (entity #1)
| |
User.cs (entity #2)
| |
AMongoCommonRepository.cs
| |
CategoryRepository.cs
| |
UserRepository.cs
| |
By this repository approach you can access these entities like before the change:
Usage
| |
In this approach there is no sharding key, but it’s easy to add it.
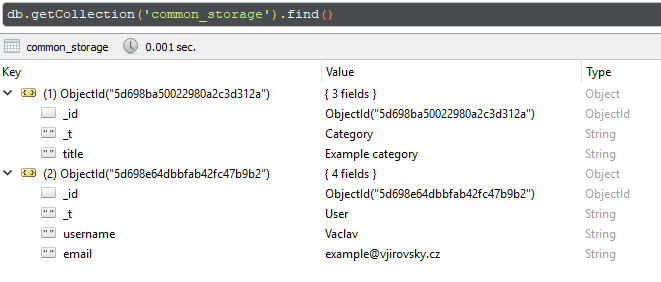
Results
As you see, SDK automatically adds discriminator attribute _t. Thanks to this attribute MongoDB SDK recognizes entity type, how to deserialize document.
Cost savings – case study
We used this approach in one project – Web API application, which has some collections with frequent access and few with infrequent access. We moved these infrequent collections to this common collection.
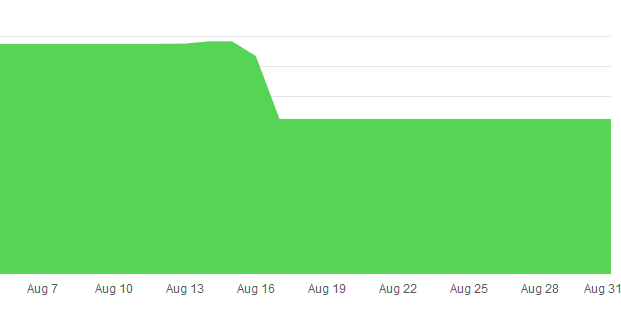
As you see, we got about -33% cost savings with fully utilized performance, without any performance issues in application (because existing prepaid reserved database performance was not utilized).
Also we still have possibility to extend performance for common collection (by granularity +-100 RU/s).
This solution will not save you every time, but for similar use cases can be really helpful.