If your workload fits into Azure Functions limits, you can save costs&time and run your executable totally serverless – you will not need to patch your OS and easily scale workloads dynamically as you need. You can pay for every invocation in consumption plan (with some free grant offered every month), or alternatively you can have dedicated App Service plan, which can be shared between multiple Function Apps (ideal for multiple small workloads to optimize your costs).
In Azure Functions you have multiple options, how to run your .exe – some of workloads can be solved even without writing a line of code, but you really need to ensure the workflow fits limitations of solution.
PowerShell wrapper
Easiest option – you don’t need to write any code (Microsoft did it instead of you) – they have created a wrapper and published on GitHub. This wrapper (written in .csx) enables you to convert executable command to HTTP endpoint.
Example of config:
| |
This example would take URL of your input file on OneDrive (as HTTP parameter inputFile), process it and answers with output file as HTTP response.
It will help you when you need to serve a console app as web service, for anything else (for example when you need to call service by alternative trigger like Timer or ServiceBus) you need to customize the wrapper.
Azure Functions custom handlers
Recently introduced feature custom handler enables to implement any programming language that supports HTTP (e.g. Go, Rust). Your executable needs to understand HTTP request and Azure Function acts as proxy (e.g. transform Blob storage trigger to HTTP request) a translate trigger/input payload into HTTP request and optionally process response.
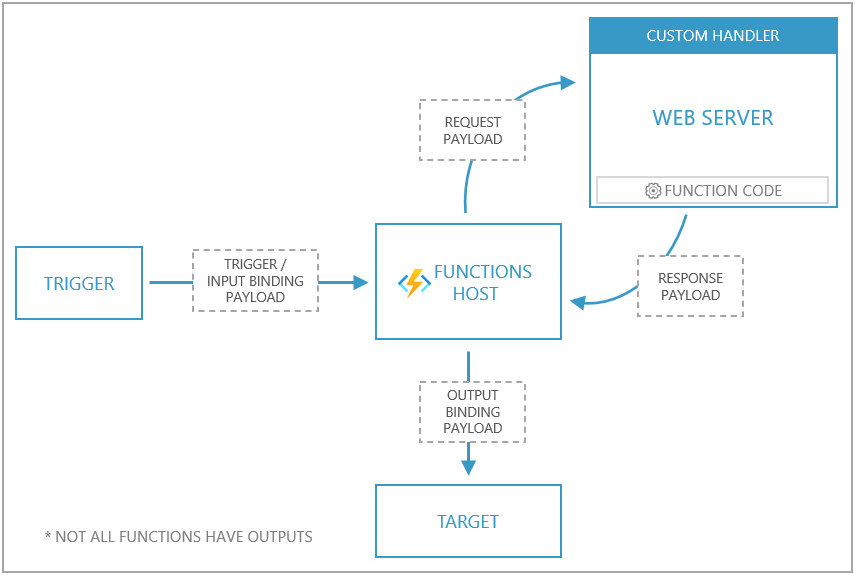
I mention this feature because some kind of workloads can be solved by this easy no code method – when you have some legacy executable working as HTTP server.
More details about custom handlers can be found on Microsoft Docs, samples on GitHub.
Writing custom wrapper
You can write custom wrapper in any of these language – C#, JavaScript (+TypeScript), F#, Java, PowerShell, Python – selection is up to you. Usually I write them in C#, but that’s my personal preferences only.
| |
Azure Functions Properties And Limitations
When you write your own wrapper, you need to know following properties and limitations about Azure Functions.
Lifecycle in Azure Functions Host
One of the most important thing you need to know about Azure Functions host is that your Function can be invocated in a new fresh host or inside re-used host. You can imagine host as an application, which performs supportive tasks (authentication, HTTP router, listening on triggers, timer planning) and when request matches route (or other trigger fires), host will trigger method Run() of static class, representing your Function.
Azure Function host is an App Service
Every Function App (I mean whole your Function App, not every Function in the app) runs in own sandbox – isolated from other Function Apps running on same machine and providing an additional degree of security. You are not permitted to perform some operations like writing to registry, open raw sockets, creating symlinks etc.
More details about sandbox can be found on GitHub.
Filesystem in App Service
All files in %HOME% (or /home on Linux) directory are persistent. When you scale out your Function App into multiple instances, this directory is shared between all of them.
Resulting effects
All above lead to some behavior you need to count with.
Constructor is called in fresh host only
| |
You could think that myInitTask() will be called during startup of host application – that’s not true, because host app uses lazy-loading, constructor will be called only during first time, when your function is triggered.
When you run the function again (in short period, usually 5-10 minutes), Azure will re-use existing host and call Run() method of your Function only. If your Function will not be called for some time, host will release it from memory and given host will be a fresh host for your Function.
If you would perform any singleton operation in constructor (for example. connection to database), check during every invocation (means in Run() method) you have valid singleton objects (timeout).
Also ensure, you clean all resources in right way in your Run() method, otherwise you can reach out limits, like socket exception, very easily.
Possible conflicts between invocations/nodes
Functions are not processed sequentially, Function host will try to save your costs/time and perform as many Functions as possible in parallel.
When you have a workload, which require an exclusive access for a shared resource you need to redesign solution or implement some locking method.
I have created a test application to illustrate this kind of conflicts – this test app was writing log in common file when invocation of Function started, wait 15 seconds and write into log file when invocation finished.
| |
As you can see, interactions with log file were overlapping – if I would have a executable, which requires to create some temp file with constant filename, it could case problems and damage outputs.
Following workaround will work at most cases – if a binary needs to create some temp files in same directory as it runs, most of them will respect current working directory and will create temp files there.
| |
In case a binary relies on TEMP variable, you can “fake” environment variable for given process:
| |